ReAct REPL Agent
The goal of this project was to investigate the capabilities of contemporary large language models (LLMs) such as GPT-3.5 and GPT-4 for discovering and chaining previously unseen APIs to execute tasks requiring multiple step-by-step actions. To achieve this, we implemented a ReAct Python-REPL agent that employs a thought-action-observation loop, enabling the agent to take external actions as python code and observe their results. One important aspect of this project is the method_search() function that allows the agent to query for specific APIs rather than enumerating all APIs in the prompt.
The full code for this project is available on GitHub .
ReAct Loop
The iterative feedback loop as proposed by the ReAct paper forms the basis of our agent. The ReAct loop interleaves reasoning and acting in a thought-action-observation loop. In each thought, it reasons about the previous observations to decide which action to take next. The action is executed by an external system, i.e. a Python REPL in our case. The result of executing that action is an observation which is fed back into the ReAct loop. These actions are Python code snippets that can have side effects, such as downloading an image or sending a chat message.
Its main power comes from three things:
- Allowing the agent to take external actions and observe their results.
- Interleaving reasoning and acting.
- Providing the LLM model a fixed pattern that it can repeat in a loop.
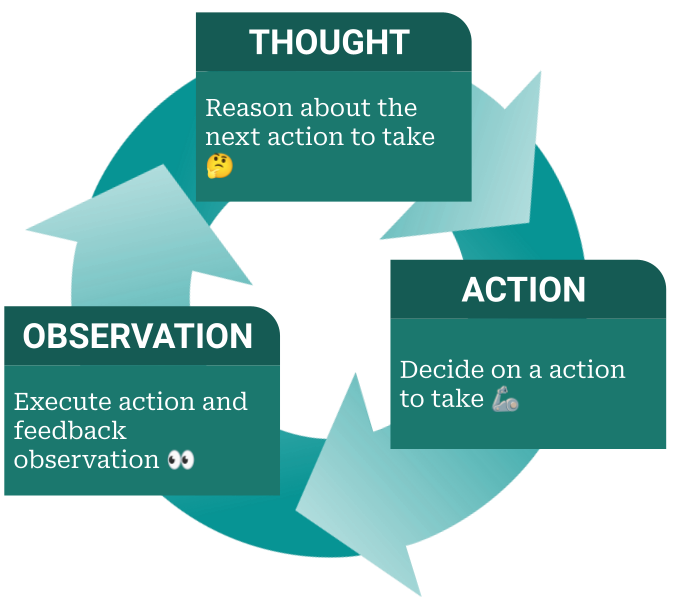
The ReAct loop is not something new, it is an implementation of the typical decision cycle such as PDCA (Plan-Do-Check-Act) or the OODA loop (Observe-Orient-Decide-Act). However, the idea of implementing this pattern in an LLM seems to work rather well.
API Index & Search
To test the ability of an LLM-based agent to chain APIs it has never seen before, we wrapped a few APIs in 15 custom Python methods and documented them. The agent can query for specific APIs by calling a method_search() method that it is made “aware” of through its prompt. This method search wraps around a simple vector index, which is a searchable index of the custom API methods, indexed by embedding of the method signatures and docstrings.
Using a descriptive query, the agent can search for API methods that might be useful. Similar to single-shot prompting, we initialize the agent’s prompt with a relevant example on how to use this method_search method to find relevant APIs
❯ method_search("Send a Discord message")
`send_message_discord(msg: str, image: Optional[Image]=None)`: Send a message to discord. An optional image to send can be provided.
`send_slack_message(msg: str, channel_id: str)`: Send a message to the Slack channel with the specified ID.
`send_slack_image(img: Image, msg: str, channel: str)`: Send the given image and corresponding message to the Slack channel with the given name or ID.
Python REPL
All ReAct actions are Python code executed with a Python interpreter. The resulting observations (stdout/stderr) are fed back to the agent. In case of any exceptions, we only show the line in the action code that fails and provide additional hints (e.g., using method_search()).
All actions are consecutively executed in a shared Python REPL, in a namespace that is passed along from the previous action to the next. This namespace is initialized with the available API methods and the method_search() function. Importing is disabled to ensure the agent cannot import any methods that are not provided to it.
ReAct Loop & API Search
The versatility of our agent is not limited to a small set of actions, as in the original ReAct paper. This flexibility is a result of all actions being written in Python code, and the method_search() method employed by the agent that allows it to explore an extensive range of APIs. However, as the number of indexed APIs increases, the significance of efficient API method retrieval becomes even more crucial.
The agent is made aware of the method_search() method at the start of the prompt. The full initial prompt is quoted below:
Execute the given task in steps. Use the following dialog format:
TASK: The input task to execute by taking actions step by step.
THOUGHT 1:
Reason step-by-step which action to take next to solve the task. Make sure no steps are forgotten. Use `method_search(description: str)` to find methods to execute each step.
ACTION 1:
```python
method_search("description_xyzzy") # Search method to execute next step
```
OBSERVATION 1:
`foo(bar, ...)`: Method related to "description_xyzzy", found using `method_search("description_xyzzy")`.
THOUGHT 2:
Reason if method `foo(bar, ...)` is useful to solve step 1. If not, call `method_search` again.
ACTION 2:
```python
bar = qux[...] # Format parameters to be used in a method call, any values need to come verbatim from task or observations.
# Make only 1 method call per action!
baz = foo(bar, ...) # Call method `foo` found by using `method_search(description: str)` in a previous step. Store the result in `baz`, which can be used in following actions. Use descriptive variable names.
print(baz) # Print the result to be shown in the next observation.
```
OBSERVATION 2:
stdout/stderr of running the previous action.
... (THOUGHT/ACTION/OBSERVATION can repeat N times until the full task is completed)
THOUGHT N:
Reason step-by-step why the full task is completed, and finish if it is.
ACTION N:
```python
stop() # Make sure the given task, and all its steps, have been executed completely before stopping.
```
Extras Instructions:
- Keep actions simple, call only 1 method per action. Don't chain method calls.
- Use descriptive variable names.
- If needed, get current date using `datetime.now()` and current location using `get_user_location() -> dict`.
- Use `print(var)` to print a variable to be shown in the next observation.
- Importing is not allowed! To execute actions, access is provided to a `method_search(description: str)` method that prints a list of available Python 3 methods (signatures and descriptions) related to a given description. Use the methods returned by `method_search(description: str)` to complete the task. These methods don't need to be imported. Pay attention to the method signatures.
- Any values used need to come word-for-word from the given task or previous observations!
This prompt leads to the agent using the method_search function when needed. See the following excerpt from this run log:
THOUGHT 5:
Based on previous observations, I have the NASA picture-of-the-day downloaded as an Image object stored in `nasa_image`. Now, I need to resize the image to half its size. I will use `method_search(description: str)` to search for methods related to "Resize the downloaded picture to half its size".
ACTION 5:
```python
method_search("Resize the downloaded picture to half its size")
```
OBSERVATION 5:
`shrink_image(image: Image, ratio: float) -> Image`: Shrink (resize) the given image by the given ratio.
`download_image(url: str) -> Image`: Download the image from the given URL and return as an Image object.
`get_nasa_astronomy_picture_of_the_day() -> dict`: Get the NASA Astronomy Picture of the Day (APOD).
THOUGHT 6:
Based on previous observations, `shrink_image(image: Image, ratio: float) -> Image` seems to be the method I need to resize the downloaded picture to half its size. I will call this method with the `nasa_image` and a ratio of 0.5 and store the result in a variable called `resized_nasa_image`.
ACTION 6:
```python
resized_nasa_image = shrink_image(nasa_image, 0.5)
print(resized_nasa_image)
```
Evaluation
We tested three different GPT models (“gpt-3.5-turbo”, “text-davinci-003”, “gpt-4”) on six different tasks. As expected, GPT-4 performed the best, completing all six tasks with only one mistake. GPT-3.5-turbo was able to finish three tasks but failed on the other three due to multiple mistakes, resulting in hitting the prompt length limit. The six tasks are:
- Print the current date.
- Send a Discord message with the current weather for my location.
- Send a Slack message to the #experimenting-with-simple-ai-agents channel with the current weather for London, UK.
- Send a descriptive Discord message with the weather forecast for the next 5 days for my location. Describe the weather each day with an appropriate emoji, include the dates in the message.
- Lookup the NASA picture-of-the day, resize to half it's size, and send to Discord with a message starting with 'Hello from Space!' and providing additional information about the image.
- What week in the last 3 months had the lowest MSFT stock closing price? Send the result including price and date to the #experimenting-with-simple-ai-agents Slack channel.
| gpt-3.5-turbo | text-davinci-003 | gpt-4 | |
|---|---|---|---|
| A | 4 ✅ | 3 ✅ | 4 ✅ |
| B | 5 ✅ | 7 ✅ | 7 ✅ |
| C | 9 ❌ | 5 🟠 | 11 ✅ |
| D | 9 🟠 | 7 ✅ | 11 ✅ |
| E | 10 ❌ | 11 ✅ | 10 ✅ |
| F | 12 ❌ | 12 ❌ | 15 ✅ |
Some general observations:
Prompting
- Zero-, single-, few-shot prompting is a killer feature. Before this project, I was trying to build a minimal workflow that could automatically execute a much simpler set of workflows by fine-tuning language models specifically for each task. The amount of data needed to tune the language model to execute a specific task correctly makes it very hard to get working. What I spend a year building, I could replicate in a few hours of working with GPT-3.
- We employed several prompting techniques to nudge the agent in the right direction:
- After the initial ReAct prompt, we force the model to do a method search on a first step in the workflow as an example of how to use the methods search.
- We prefix the THOUGHT steps with “Based on previous observations,” to force reasoning about what it observed.
- When an exception occurs, we may provide extra information in the OBSERVATION to help the agent make the next step correctly.
- A lot of the prompting techniques above were initially needed to get “text-davinci-003” to execute the tasks somewhat consistently. Not all of these are needed to get good results with GPT-4.
- Even though models are getting better, prompt engineering will not disappear soon. Someone will have to instruct these models, because the alternative, gathering data to fine-tune (see previous point), just takes a tremendous amount of work. That being said, I believe that as instruction-aligning these models improves, prompt engineering is going to become less arcane and more straightforward.
- Patterns are important! They can be used productively, e.g. to set up the ReAct steps. However, sometimes they also make the agent get stuck in a repeating loop.
Hallucinations
Despite specific instructions to use values verbatim from tasks or observations, the agent sometimes hallucinates. For example, hallucinating geo-coordinates. Or hallucinating methods that don’t exist. The latter one is not an issue, and could actually be a feature because these hallucinations could be used to search for an existing method instead.
Contributions
Thanks to Vulume for the brainstorming and hacking sessions on an early stage of this project, and proofreading this post!
The full code for this project is available on GitHub .
LLM ReAct Loop Agents