This last part of our tutorial on how to implement a neural network, generalizes the single layer feedforward neural network into any number of layers. The concepts of a linear projection via matrix multiplication and non-linear transformation will be generalized. The usage of the generalization will be illustrated by building a small feedforward network that consists of two hidden layers to classify handwritten digits. This network will be trained by stochastic gradient descent , a popular variant of gradient descent that updates the parameters each step on only a subset of the parameters.
This part will cover:
- Generalization to multiple layers
- Minibatches with stochastic gradient descent
This is the last part of a 5-part tutorial on how to implement neural networks from scratch in Python:
- Part 1: Gradient descent
- Part 2: Classification
- Part 3: Hidden layers trained by backpropagation
- Part 4: Vectorization of the operations
- Part 5: Generalization to multiple layers (this)
The notebook starts out with importing the libraries we need:
# Imports
%matplotlib inline
%config InlineBackend.figure_formats = ['svg']
import itertools
import collections
import numpy as np # Matrix and vector computation package
# data and evaluation utils
from sklearn import datasets, model_selection, metrics
import matplotlib
import matplotlib.pyplot as plt # Plotting library
from matplotlib.colors import colorConverter, ListedColormap
import seaborn as sns # Fancier plots
# Set seaborn plotting style
sns.set_style('darkgrid')
# Set the seed for reproducability
np.random.seed(seed=1)
#
Handwritten digits dataset
The dataset used in this tutorial is the digits dataset provided by scikit-learn . This dataset consists of 1797 8x8 images of handwritten digits between 0 and 9. Each 8x8 pixel image is provided as a flattened input vector of 64 variables. Example images for each digit are shown below. Note that this dataset is different from the larger and more famous MNIST dataset. The smaller dataset from scikit-learn was chosen to minimize training time for this tutorial. Feel free to experiment and adapt this tutorial to classify the MNIST digits.
The dataset will be split into:
-
A training set used to train the model. (inputs:
X_train, targets:T_train) -
A validation set used to validate the model performance and to stop training if the model starts
overfitting
on the training data. (inputs:
X_validation, targets:T_validation) -
A final
test set
to evaluate the trained model on data is independent of the training and validation data. (inputs:
X_test, targets:T_test)
# Load the data from scikit-learn.
digits = datasets.load_digits()
# Load the targets.
# Note that the targets are stored as digits, these need to be
# converted to one-hot-encoding for the output sofmax layer.
T = np.zeros((digits.target.shape[0], 10))
T[np.arange(len(T)), digits.target] += 1
# Divide the data into a train and test set.
(X_train, X_test, T_train, T_test
) = model_selection.train_test_split(digits.data, T, test_size=0.4)
# Divide the test set into a validation set and final test set.
(X_validation, X_test, T_validation, T_test
) = model_selection.train_test_split(X_test, T_test, test_size=0.5)
# Plot an example of each image.
fig, axs = plt.subplots(nrows=1, ncols=10, figsize=(10, 1))
for i, ax in enumerate(axs):
ax.imshow(digits.images[i], cmap='binary')
ax.set_axis_off()
plt.show()
#
Generalization of the layers
Part 4
of this tutorial series took on the classical view of neural networks where each layer consists of a
linear transformation
by a
matrix multiplication
and vector addition followed by a non-linear function.
Here the linear transformation is split from the non-linear function and each is abstracted into its own layer. This has the benefit that the forward and backward step of each layer can easily be calculated separately.
This tutorial defines three example layers as Python classes :
-
A layer to apply the linear transformation (
LinearLayer). -
A layer to apply the logistic function (
LogisticLayer). -
A layer to compute the softmax classification probabilities at the output (
SoftmaxOutputLayer).
Each layer can compute its output in the forward step with
get_output
, which can then be used as the input for the next layer. The gradient at the input of each layer in the backpropagation step can be computed with
get_input_grad
. This function computes the gradient with the help of the targets if it's the last layer, or the gradients at its outputs (gradients at input of next layer) if it's an intermediate layer.
Each layer has the option to
iterate
over the parameters (if any) with
get_params_iter
, and get the gradients of these parameters in the same order with
get_params_grad
.
Notice that the gradient and cost computed by the softmax layer are divided by the number of input samples. This is to make this gradient and cost independent of the number of input samples so that the size of the mini-batches can be changed without affecting other parameters. More on this later.
# Non-linear functions used
def logistic(z):
return 1 / (1 + np.exp(-z))
def logistic_deriv(y): # Derivative of logistic function
return np.multiply(y, (1 - y))
def softmax(z):
return np.exp(z) / np.sum(np.exp(z), axis=1, keepdims=True)
# Layers used in this model
class Layer(object):
"""Base class for the different layers.
Defines base methods and documentation of methods."""
def get_params_iter(self):
"""Return an iterator over the parameters (if any).
The iterator has the same order as get_params_grad.
The elements returned by the iterator are editable in-place."""
return []
def get_params_grad(self, X, output_grad):
"""Return a list of gradients over the parameters.
The list has the same order as the get_params_iter iterator.
X is the input.
output_grad is the gradient at the output of this layer.
"""
return []
def get_output(self, X):
"""Perform the forward step linear transformation.
X is the input."""
pass
def get_input_grad(self, Y, output_grad=None, T=None):
"""Return the gradient at the inputs of this layer.
Y is the pre-computed output of this layer (not needed in
this case).
output_grad is the gradient at the output of this layer
(gradient at input of next layer).
Output layer uses targets T to compute the gradient based on the
output error instead of output_grad"""
pass
class LinearLayer(Layer):
"""The linear layer performs a linear transformation to its input."""
def __init__(self, n_in, n_out):
"""Initialize hidden layer parameters.
n_in is the number of input variables.
n_out is the number of output variables."""
self.W = np.random.randn(n_in, n_out) * 0.1
self.b = np.zeros(n_out)
def get_params_iter(self):
"""Return an iterator over the parameters."""
return itertools.chain(
np.nditer(self.W, op_flags=['readwrite']),
np.nditer(self.b, op_flags=['readwrite']))
def get_output(self, X):
"""Perform the forward step linear transformation."""
return (X @ self.W) + self.b
def get_params_grad(self, X, output_grad):
"""Return a list of gradients over the parameters."""
JW = X.T @ output_grad
Jb = np.sum(output_grad, axis=0)
return [g for g in itertools.chain(
np.nditer(JW), np.nditer(Jb))]
def get_input_grad(self, Y, output_grad):
"""Return the gradient at the inputs of this layer."""
return output_grad @ self.W.T
class LogisticLayer(Layer):
"""The logistic layer applies the logistic function to its inputs."""
def get_output(self, X):
"""Perform the forward step transformation."""
return logistic(X)
def get_input_grad(self, Y, output_grad):
"""Return the gradient at the inputs of this layer."""
return np.multiply(logistic_deriv(Y), output_grad)
class SoftmaxOutputLayer(Layer):
"""The softmax output layer computes the classification
propabilities at the output."""
def get_output(self, X):
"""Perform the forward step transformation."""
return softmax(X)
def get_input_grad(self, Y, T):
"""Return the gradient at the inputs of this layer."""
return (Y - T) / Y.shape[0]
def get_cost(self, Y, T):
"""Return the cost at the output of this output layer."""
return - np.multiply(T, np.log(Y)).sum() / Y.shape[0]
Sample model
The following sections will refer to a layer as a layer defined above, and hidden-layer or output-layer as the classical neural network view of a linear transformation followed by a non-linear function.
The sample model used to classify the handwritten digits in this tutorial consists of two hidden-layers with logistic functions and a softmax output-layer. The fist hidden-layer takes a vector of 64 pixel values and transforms them to a vector of 20 values. The second hidden-layer projects the previous 20 values to 20 new values. The output-layer outputs probabilities for the 10 possible classes. This architecture is illustrated in the following figure (biases are not shown to keep figure clean).
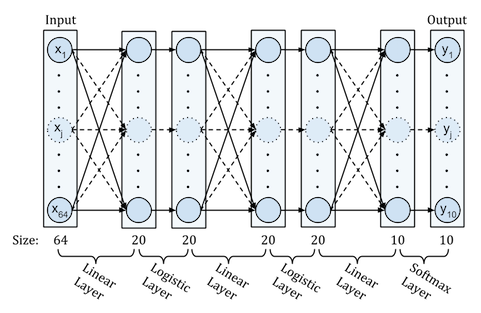
The full network is represented as a sequential list where each next layer is added on top of the previous layer by putting it in the next position in the list. The first layer is at position 0 in this list, the last layer is at the last index of this list.
# Sample model to be trained on the data
hidden_neurons_1 = 20 # Number of neurons in the first hidden-layer
hidden_neurons_2 = 20 # Number of neurons in the second hidden-layer
# Create the model
layers = [] # Define a list of layers
# Add first hidden layer
layers.append(LinearLayer(X_train.shape[1], hidden_neurons_1))
layers.append(LogisticLayer())
# Add second hidden layer
layers.append(LinearLayer(hidden_neurons_1, hidden_neurons_2))
layers.append(LogisticLayer())
# Add output layer
layers.append(LinearLayer(hidden_neurons_2, T_train.shape[1]))
layers.append(SoftmaxOutputLayer())
Backpropagation
The details of how backpropagation works in the forward and backward step of vectorized model are explained in part 4 of this tutorial. This section will only illustrate how to perform backpropagation over any number of layers with the generalized model described here.
Forward step
The forward steps are computed by the
forward_step
method defined below. This method iteratively computes the outputs of each layer and feeds it as input to the next layer until the last layer. Each layer's output is computed by calling the
get_output
method. These output activations are stored in the
activations
list.
# Forward propagation step as a method.
def forward_step(input_samples, layers):
"""
Compute and return the forward activation of each layer in layers.
Input:
input_samples: A matrix of input samples (each row
is an input vector)
layers: A list of Layers
Output:
A list of activations where the activation at each index
i+1 corresponds to the activation of layer i in layers.
activations[0] contains the input samples.
"""
activations = [input_samples] # List of layer activations
# Compute the forward activations for each layer starting
# from the first
X = input_samples
for layer in layers:
# Get the output of the current layer
Y = layer.get_output(X)
# Store the output for future processing
activations.append(Y)
# Set the current input as the activations of the previous layer
X = activations[-1]
return activations
Backward step
The gradients computed in the backward step are computed by the
backward_step
method defined below. The backward step goes over all the layers in the reversed order. It first gets the initial gradients from the output layer and uses these gradients to compute the gradients of the layers below by iteratively calling the
get_input_grad
method. During each step, it computes the gradients of the cost with respect to the parameters by calling the
get_params_grad
method and returns them in a list.
# Define the backward propagation step as a method
def backward_step(activations, targets, layers):
"""
Perform the backpropagation step over all the layers and return the parameter gradients.
Input:
activations: A list of forward step activations where the activation at
each index i+1 corresponds to the activation of layer i in layers.
activations[0] contains the input samples.
targets: The output targets of the output layer.
layers: A list of Layers corresponding that generated the outputs in activations.
Output:
A list of parameter gradients where the gradients at each index corresponds to
the parameters gradients of the layer at the same index in layers.
"""
param_grads = collections.deque() # List of parameter gradients for each layer
output_grad = None # The error gradient at the output of the current layer
# Propagate the error backwards through all the layers.
# Use reversed to iterate backwards over the list of layers.
for layer in reversed(layers):
Y = activations.pop() # Get the activations of the last layer on the stack
# Compute the error at the output layer.
# The output layer error is calculated different then hidden layer error.
if output_grad is None:
input_grad = layer.get_input_grad(Y, targets)
else: # output_grad is not None (layer is not output layer)
input_grad = layer.get_input_grad(Y, output_grad)
# Get the input of this layer (activations of the previous layer)
X = activations[-1]
# Compute the layer parameter gradients used to update the parameters
grads = layer.get_params_grad(X, output_grad)
param_grads.appendleft(grads)
# Compute gradient at output of previous layer (input of current layer):
output_grad = input_grad
return list(param_grads) # Return the parameter gradients
Gradient Checking
As in part 4 of this tutorial the gradient computed by backpropagation is compared with the numerical gradient to assert that there are no bugs in the code to compute the gradients.
The code below gets the parameters of each layer by the help of the
get_params_iter
method that returns an iterator over all the parameters in the layer. The order of parameters returned corresponds to the order of parameter gradients returned by
get_params_grad
during backpropagation.
# Perform gradient checking
# Test the gradients on a subset of the data
nb_samples_gradientcheck = 10
X_temp = X_train[0:nb_samples_gradientcheck,:]
T_temp = T_train[0:nb_samples_gradientcheck,:]
# Get the parameter gradients with backpropagation
activations = forward_step(X_temp, layers)
param_grads = backward_step(activations, T_temp, layers)
# Set the small change to compute the numerical gradient
eps = 0.0001
# Compute the numerical gradients of the parameters in all layers.
for idx in range(len(layers)):
layer = layers[idx]
layer_backprop_grads = param_grads[idx]
# Compute the numerical gradient for each parameter in the layer
for p_idx, param in enumerate(layer.get_params_iter()):
grad_backprop = layer_backprop_grads[p_idx]
# + eps
param += eps
plus_cost = layers[-1].get_cost(
forward_step(X_temp, layers)[-1], T_temp)
# - eps
param -= 2 * eps
min_cost = layers[-1].get_cost(
forward_step(X_temp, layers)[-1], T_temp)
# reset param value
param += eps
# calculate numerical gradient
grad_num = (plus_cost - min_cost) / (2*eps)
# Raise error if the numerical grade is not close to the
# backprop gradient
if not np.isclose(grad_num, grad_backprop):
raise ValueError((
f'Numerical gradient of {grad_num:.6f} is '
'not close to the backpropagation gradient '
f'of {grad_backprop:.6f}!'))
print('No gradient errors found')
#
Stochastic gradient descent backpropagation
This tutorial uses a variant of gradient descent called Stochastic gradient descent (SGD) to optimize the cost function. SGD follows the negative gradient of the cost function on subsets of the total training set. This has a few benefits: One of them is that the training time on large datasets can be reduced because the matrix of samples is much smaller during each sub-iteration and the gradients can be computed faster and with less memory. Another benefit is that computing the cost function on subsets results in noise, i.e. each subset will give a different cost depending on the samples. This will result in noisy (stochastic) gradient updates which might be able to push the gradient descent out of local minima. These, and other, benefits contribute to the popularity of SGD on training large scale machine learning methods such as neural networks.
The cost function needs to be independent of the number of input samples because the size of the subsets used during SGD can vary. This is why the mean squared error (MSE) cost function is used instead of just the squared error. Using the mean instead of the sum is reflected in the gradient and cost computed by the softmax layer being divided by the number of input samples.
Minibatches
The subsets of the training set are often called mini-batches. The following code will divide the training set into mini-batches of around 25 samples per batch. The inputs and targets are combined together in a list of (input, target) tuples.
# Create the minibatches
batch_size = 25 # Approximately 25 samples per batch
nb_of_batches = X_train.shape[0] // batch_size # Number of batches
# Create batches (X,Y) from the training set
XT_batches = list(zip(
np.array_split(X_train, nb_of_batches, axis=0), # X samples
np.array_split(T_train, nb_of_batches, axis=0))) # Y targets
SGD updates
The parameters $\mathbf{\theta}$ of the network are updated by the
update_params
method that iterates over each parameter of each layer and applies the simple
gradient descent
rule on each mini-batch: $\mathbf{\theta}(k+1) = \mathbf{\theta}(k) - \Delta \mathbf{\theta}(k+1)$. $\Delta \mathbf{\theta}$ is defined as: $\Delta \mathbf{\theta} = \mu \frac{\partial \xi}{\partial \mathbf{\theta}}$ with $\mu$ the learning rate.
The update steps will be performed for a number of iterations (
nb_of_iterations
) over the full training set, where each full iterations consists of multiple updates over the mini-batches. After each full iteration, the resulting network will be tested on the validation set. The training will stop if the cost on the validation set doesn't increase after three full iterations to prevent overfitting or after maximum 300 iterations. All costs will be stored in between for future analysis.
# Define a method to update the parameters
def update_params(layers, param_grads, learning_rate):
"""
Function to update the parameters of the given layers with the given
gradients by gradient descent with the given learning rate.
"""
for layer, layer_backprop_grads in zip(layers, param_grads):
for param, grad in zip(layer.get_params_iter(),
layer_backprop_grads):
# The parameter returned by the iterator point to the
# memory space of the original layer and can thus be
# modified inplace.
param -= learning_rate * grad # Update each parameter
# Perform backpropagation
# initalize some lists to store the cost for future analysis
batch_costs = []
train_costs = []
val_costs = []
max_nb_of_iterations = 300 # Train for a maximum of 300 iterations
learning_rate = 0.1 # Gradient descent learning rate
# Train for the maximum number of iterations
for iteration in range(max_nb_of_iterations):
for X, T in XT_batches: # For each minibatch sub-iteration
# Get the activations
activations = forward_step(X, layers)
# Get cost
batch_cost = layers[-1].get_cost(activations[-1], T)
batch_costs.append(batch_cost)
# Get the gradients
param_grads = backward_step(activations, T, layers)
# Update the parameters
update_params(layers, param_grads, learning_rate)
# Get full training cost for future analysis (plots)
activations = forward_step(X_train, layers)
train_cost = layers[-1].get_cost(activations[-1], T_train)
train_costs.append(train_cost)
# Get full validation cost
activations = forward_step(X_validation, layers)
validation_cost = layers[-1].get_cost(
activations[-1], T_validation)
val_costs.append(validation_cost)
if len(val_costs) > 3:
# Stop training if the cost on the validation set doesn't
# decrease for 3 iterations
if val_costs[-1] >= val_costs[-2] >= val_costs[-3]:
break
# The number of iterations that have been executed
nb_of_iterations = iteration + 1
The costs stored during training can be plotted to visualize the performance during training. The resulting plot is shown in the next figure. The cost on the training samples and validation samples goes down very quickly and flattens out after about 40 iterations on the full training set. Notice that the cost on the training set is lower than the cost on the validation set, this is because the network is optimized on the training set and is slightly overfitting. The training stops after around 90 iterations because the validation cost stops decreasing.
Also, notice that the cost of the mini-batches fluctuates around the cost of the full training set. This is the stochastic effect of mini-batches in SGD.
# Plot the minibatch, full training set, and validation costs
batch_x_inds = np.linspace(
0, nb_of_iterations, num=nb_of_iterations*nb_of_batches)
iteration_x_inds = np.linspace(
1, nb_of_iterations, num=nb_of_iterations)
# Plot the cost over the iterations
plt.figure(figsize=(6, 4))
plt.plot(batch_x_inds, batch_costs,
'k-', linewidth=0.5, label='cost minibatches')
plt.plot(iteration_x_inds, train_costs,
'r-', linewidth=2, label='cost full training set')
plt.plot(iteration_x_inds, val_costs,
'b-', linewidth=3, label='cost validation set')
# Add labels to the plot
plt.xlabel('iteration')
plt.ylabel('$\\xi$', fontsize=12)
plt.title('Decrease of cost over backprop iteration')
plt.legend()
# x1, x2, y1, y2 = plt.axis()
plt.axis((0, nb_of_iterations, 0, 2.5))
plt.show()
#
Performance on the test set
Finally, the
accuracy
on the independent test set is computed to measure the performance of the model. The
scikit-learn
accuracy_score
method is used to compute this accuracy from the predictions made by the model. The final accuracy on the test set is $96\%$ as shown below.
The results can be analyzed in more detail with the help of a
confusion table
. This table shows how many samples of which class are classified as one of the possible classes. The confusion table is shown in the figure below. It is computed by the
scikit-learn
confusion_matrix
method.
Notice that the digit '8' is misclassified five times, two times as '2', two times as '5', and one time as '9'.
# Get results of test data
# Get the target outputs
y_true = np.argmax(T_test, axis=1)
# Get activation of test samples
activations = forward_step(X_test, layers)
# Get the predictions made by the network
y_pred = np.argmax(activations[-1], axis=1)
# Test set accuracy
test_accuracy = metrics.accuracy_score(y_true, y_pred)
print(f'The accuracy on the test set is {test_accuracy:.0%}')
#
# Show confusion table
# Get confustion matrix
conf_matrix = metrics.confusion_matrix(y_true, y_pred, labels=None)
# Plot the confusion table
# Digit class names
class_names = [f'${x:d}$' for x in range(0, 10)]
with sns.axes_style("white"):
fig, ax = plt.subplots(nrows=1, ncols=1)
# Show class labels on each axis
ax.xaxis.tick_top()
major_ticks = range(0, 10)
minor_ticks = [x + 0.5 for x in range(0, 10)]
ax.xaxis.set_ticks(major_ticks, minor=False)
ax.yaxis.set_ticks(major_ticks, minor=False)
ax.xaxis.set_ticks(minor_ticks, minor=True)
ax.yaxis.set_ticks(minor_ticks, minor=True)
ax.xaxis.set_ticklabels(class_names, minor=False, fontsize=12)
ax.yaxis.set_ticklabels(class_names, minor=False, fontsize=12)
# Set plot labels
ax.yaxis.set_label_position("right")
ax.set_xlabel('Predicted label')
ax.set_ylabel('True label')
fig.suptitle('Confusion table', y=1.03, fontsize=12)
# Show a grid to seperate digits
ax.grid(b=True, which=u'minor')
# Color each grid cell according to the number classes predicted
ax.imshow(conf_matrix, interpolation='nearest', cmap='binary')
# Show the number of samples in each cell
for x in range(conf_matrix.shape[0]):
for y in range(conf_matrix.shape[1]):
color = 'w' if x == y else 'k'
ax.text(x, y, conf_matrix[y,x],
ha="center", va="center", color=color)
plt.show()
#
This was the last part of a 5-part tutorial on how to implement neural networks from scratch in Python:
# Python package versions used
%load_ext watermark
%watermark --python
%watermark --iversions
#